
The idea of “good code” is a topic for heated debate. While there are overarching ideas like good naming, using patterns, and abstracting to the conditions, the act of writing good code itself can still be a hard task to implement.
When it comes to good code, there are three ingredients you need to take into consideration — the requirements, the architecture, and how you capture ideas. In this piece, we will go over these three ingredients and how to think in a way that is conducive to “good code”.
But before we begin, we need to understand what “good code” is.
What Is Good Code? What Does It Look Like? Why Does It Matter?
“Good code” by nature is an evolving practice. For some, good code can mean code that comes with a full suite of unit tests. For others, it can mean implementing composition patterns over inheritance patterns. Tests and pattern implementations are debatable components for the definition of “good code” because they are opinionated.
However, there are certain traits that developers are in consensus about. In a nutshell, “good code” is code that is easily accessible and maintainable by the development team. This means that comprehension and extensibility are easily achieved by another developer. The code’s structure and architecture are externalized. It is decoupled from the author and will live longer than the sprint it was created in.
In terms of design, “good code” looks orderly, with clear implemented patterns (whatever that pattern may be), and is structured in alignment with conventions rather than invented and for single-use solutions. “Good code” matters because it implements standardized practices to address common vulnerabilities, makes debugging easier, and ensures that future extensions are able to achieve modularity with the application.
So how do you create “good code”? Let’s begin with the first ingredient — decrypting the requirements.
First Ingredient: Decrypting The Requirements
The major mistake that any developer can commit is jumping into the code head first. This means that the developer may not have a full understanding of what exactly they are coding. When this happens, it’s like trying to build a house without any blueprints or specifications. You just have a rough idea of what it should look like, then go about gathering all your bits and pieces, hoping that they’d all fit together without any measurement.
So before you start coding, figure out exactly what you need, why you need it, and how each of the pieces is expected to fit together. This is the foundation of good code and leaves room for modifications and growth without being too tied to the code. Any errors or miscalculations are detected before you get too far into the coding process.
Blueprinting can feel like a long process but it’s actually part of the code. When you blueprint out your code, it can lead to better object construction. It’s easy to get things up and running without much thought, but preplanning your objects can work in your favor. For JavaScript, it can lead to better prototyped objects. For Java, it can help you construct better objects and children.
Most applications are constructed using a form of object-oriented language (OOP). The concept behind object-oriented is to help you organize and create hierarchies with your ideas. However, if you are unclear about what your idea is, you can’t truly implement object-oriented in a way that is efficient and maximizes its benefits. Object-oriented works by categorizing contents, meaning that you need to identify what exactly you are trying to encapsulate in code before you start coding.
Bad code happens when this process isn’t followed. As a result, developers end up with an ad-hoc creation that is prone to brittleness and unwanted mutations. So figure out your requirements before you start coding, it can save you and your future fellow developers from unnecessary time wastage trying to match code that is unmatchable against the requirements.
Second Ingredient: Constructing Your Architecture
Architecture is often secondary and disregarded when it comes to creating applications. There are also two types of architecture — folder/file structure and code structure.
Folder and file structures are often an afterthought and can cause organizational disarray. It also contributes to how well your separation of concerns is implemented. Separation of concern is how your code is organized. The popular method is to organize it by code type. For example, in Angular, separation of concern in a component is structured through three different files – the HTML view, the typeScript component, and CSS for any cosmetic styling. In contrast, React flips this separation of concern structure and combines them in a cross-section manner to form one file, with each feature stacked on top of the other.
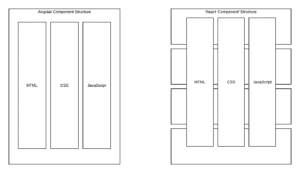
Example of Angular vs. React component structure. Angular works on siloed code while React is cross-sectional by design.
Frameworks and libraries can also dictate what your folder/file structure is like. While this is helpful to maintaining convention, it doesn’t always guarantee that “good code” will be the result. The complementary part of achieving “good code” via architecture is also your code structure.
Modularity relies on the idea that your code is isolated from each other enough that it won’t break if something else changes. While dependencies are an inescapable part of the application building, true modularity won’t create errors if a change is implemented elsewhere. To achieve this, clear interfaces into your modules are required.
However, sometimes code needs to change and that will break the application. To solve this issue, your offending module needs to be clear enough for bridge patterns to be implemented. This doesn’t mean that the original module is bad. Rather, it might just be a case of aging code. Aging code is not always necessarily bad code if it can be interfaced and connected back into the original app with ease. Most of the time, ease is gauged through the number of interfaces it needs to connect to. The general rule is, less is better. A single entry point is often best.
Third Ingredient: Capturing And Transforming Ideas Into Code
The task of capturing and transforming ideas into code can be complicated. Our primary task as developers is to simplify it. The process of simplification is often achieved through abstraction.
However, don’t confuse abstraction with making things as vague as possible. Abstracting code means taking it down to its core value and purpose of existing. It is defined with clear intentions.
We often say that “good code” is self documenting. However, we often fail to implement it by not capturing the nature of what we’re trying to code. This is best explained through an example. Here is a hypothetical function in JavaScript. Can you guess what it does?
All we know from the above code is that it runs a list, adds a price, and returns a total. But which list? The total price of what? Why do we need to run this list? There are too many unanswered questions.
Based on the above code, a developer reading it may not connect what the code is trying to represent. While it is abstracted into its purest form, it is so vague that it could be anything. The dependency array has a generic name and debug tracing makes it hard to figure out the source. If something went wrong in array, we wouldn’t know where to start looking for the source.
The name of the function isn’t any better. What is runList supposed to do? Sure, we know it runs a list, but why? There is no information about the context in the code, except maybe through array[i].price, but that could be the price of the stock, the price of the cart, the price of the discounts, or the price of past purchases.
Another issue with the code above is using i. While this is a standard tutorial-based convention, it is something that should be left in the learning space. i as a representation is too generic and doesn’t tell you anything, other than being a counter. It also creates a potential problem – what if you have more than one loop? what if i is already declared elsewhere? This is how a domino cascade effect can begin.
Now that we’ve gone over an example of bad JavaScript code, let’s look at the refactored good version:
While on the surface this code looks longer than the original version, it is information-rich. You don’t need to explain what this function is trying to achieve. It has a single purpose — to get the cart total. It achieves this by looping through the cartItems array and adding each price based on the item’s position. When it’s all done, the cartTotal is returned to be consumed by whatever called it.
This is the essence of what good code through self-documentation is supposed to look like.
Final Thoughts
Putting it all together requires a level of code orchestration. Planning is a vital part of coding because the time spent trying to unravel bad code often outweighs the task of figuring things out before you boot up your favorite IDE.
All code ages with each iteration, updates, and upgrades. The difference between good and bad code is that the first ages more gracefully and degrades at a slower rate. Change is inevitable to any piece of software. Good code is able to handle it with more grace and is easier to move around.
In short, “good code” is code that is able to communicate its intention in a structured and coherent manner that is modular by nature.
I hope you found this piece interesting. Thank you for reading.






