
When writing software code, the ideal best practice is to write it without any bugs. However, even if it were possible to write bugless software, the modular nature of software development makes it impossible to do so because of the libraries and legacy code snippets used during development that may create bugs and open security vulnerabilities.
Since the issue of “Smashing the stack for fun and profit” by Alp1 in 1960, buffer overflows continue to be one of the most crucial vulnerabilities in the Information Security Domain.
Since then, various buffer overflow vulnerabilities have been discovered and reported.
What are buffer overflow attacks?
Buffer overflow attacks generally occur when you try to write to a memory location you do not own. The main reason behind them is poorly implemented bound checking on user input. Due to this, user-supplied input is written into the wrong memory space.
For example, consider a bucket with a capacity of 1 liter. You want to fill that bucket with water and keep the floor dry. You start filling the bucket with water, and after a while, that bucket will be full. If you do not stop, water will spill on the floor, a place where you did not intend to fill water.
The same goes for the buffer overflow attacks.
Example #1
A programmer implements a function that initializes a buffer space in memory with the capacity to store 20 characters, thinking that users will only enter up to 20 characters. However, the developer forgets to implement a check to assert that the user input id is less than 20 characters.
If a user enters an input larger than 25 characters, the spillover of 5 characters will be written in memory locations adjacent to the allocated buffer, overwriting any data that was initially stored there.
In simple cases, the overwritten space does not belong to the user, resulting in a segmentation fault, and the program will crash. Usually, this would not seem like much of a big deal. However, when this happens to production-level software, which is supposed to run seamlessly without any maintenance for an extended period, such as a web server, it will immediately crash. This crash would cause a DOS, i.e., Denial of Service attack, resulting in the server becoming unavailable to everyone.
Example #2
What if the person causing the buffer overflow is not just an uninformed user but an infamous hacker who is trying to compromise your application? With precision, it is possible to control the behavior of the buffer overflow.
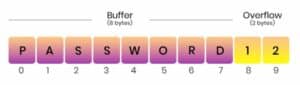
Suppose you have developed an application that protects users’ files with passwords, but your password checking functionality has a buffer overflow vulnerability. You estimated that the password would not be longer than five characters and allocated space accordingly. A password like PASS would be acceptable.
However, if a user uses PASSWORD as their password, only PASSW will be stored in the initialized buffer. ORD will be written in a different, adjacent location, possibly overwriting existing data.
To check whether the password is correct or not, you compare it with the initially configured password, stored in a memory location of the program. If an attacker can control the location of where overflowed characters (i.e., ORD) got written, they can store these characters where the correct password was written, causing the new password to become ORD. This results in a complete compromise of the application.
Like this, every year, tons of exploits and vulnerabilities are publicly disclosed on platforms such as Exploit-db, PacketstormSecurity, and more. Even attackers with less experience in buffer overflow attacks can make use of the publicly disclosed exploits and compromise the vulnerable software.
Protecting Against Buffer Overflow Attacks
To protect against buffer overflow attacks, we should know how buffer overflow attacks are performed.
Exploitation
Here, we will walk through a common type of buffer overflow attack called Stack Overflow. But first, we need to know various terms related to memory and buffer.
Stack
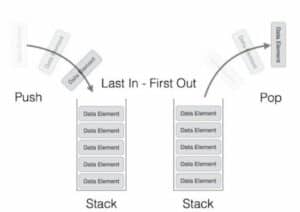
Stacks are data structures of a fixed size where you can store a collection of objects. Objects in the stack obey the LIFO rule, i.e., Last in First out.
You can consider a stack as a pile of trays put together, one on top of the other. The last tray you place would be the first one to be removed.
Two operations can be done on the stack:
- PUSH – This instruction pushes the object on the top of the stack
- POP – This instruction removes the object from the top of the stack
Here, the ESP register points to the top of the stack meanwhile EBP points to the base of the stack.
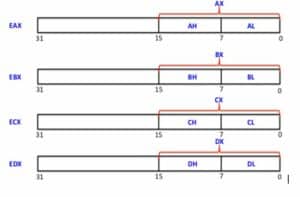
Registers
Registers are like variables you use in programming. They help the CPU determine the flow of program execution.
There are various types of registers:
- General purpose registers – EAX, EBX
- Segment – CS, CD
- Control – EIP
For buffer overflow attacks, we will focus on EIP, i.e., Extended Instruction Pointer.
Any program is a set of instructions to the CPU where it starts executing instructions from the top. EIP points to the address of the next executable instruction.
For example, consider the following program. At the start, EIP will contain the entry point’s address to the program, and the CPU executes that instruction. Then, EIP is incremented to point to the next instruction to be executed. CPU executes the instruction stored at the address indicated by the EIP. EIP can also manipulate loops, jumps, if-else statements, and more.
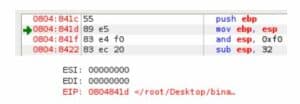
Refer to the above image where, just like the green arrow, EIP points to the next executable instruction.
Various functions are vulnerable to buffer overflow attacks by design, such as gets, strcat, etc.
Let’s look at the following C program,
This program takes input from the program argument and tries to store it into the buffer of size 5. Let us compile and run the program with the command:
gcc bof.c -o bof -fno-stack-protector -m32 -z execstack
Now let’s execute this command with an argument.

This will execute successfully, but if we supply more characters,

The program will throw segmentation fault, indicating that we have successfully overflown the buffer and the program has crashed.
Now let us see the stack trace of this execution to see what exactly happens behind the scene.

After executing this command, we can see which system calls were made and how the execution happened.
Near the end, we can see that this too results in a segmentation fault but here, we can also see that it resulted from an invalid address in si_addr. We have overwritten si_addr, which decides which address contains the next instruction with 0x41414141. I.e., several AAA we supplied resulted in a direct overwrite to the EIP.

Now let us see how this technique can be utilized to get more access to the computer running the program.
Take a look at the following program.
This program contains two functions:
- vuln: executed from main
- An obfuscated function: according to the comment, never gets executed
Our task is to execute the obfuscated function to retrieve the flag and run the /bin/sh.
Now let us run the program.

We supply a large input of 99 ‘A’ characters with the help of Python, and we get the segmentation fault indicating the buffer overflow.

Running the strace, we can see that we have overwritten the si_addr with a bunch of AA.
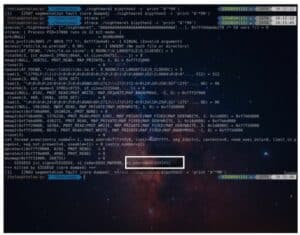
Now we just need to find which occurrence of AA caused the program to overflow, so we need to find the offset. For that, we generate a string with an online buffer overflow EIP offset String generator.

We copy the string and supply it in the program’s argument; then, we find out the new value of si_addr overwritten by the string.
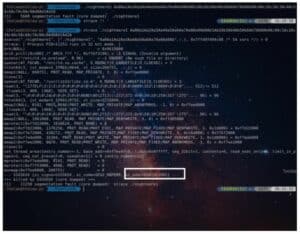
After putting the si_addr value into the offset generator, we get the offset 28

This means that the program’s buffer can contain 28 characters before it gets overflown, so after the 28th character, whatever we provide will get overwritten to the si_addr, executing instructions stored there.
As our initial goal was to execute the mysterious function, we can find the address of that function and overwrite the si_addr with its address.
The following command can be used to find addresses of all functions.

So taking the address 08048454, we should pass the address after the 28th character to execute the mysterious function. But as we are working on the binary, which follows the Little Endian Byte Order, we write bytes from right to left. I.e., 08048454 becomes 54840408, and we convert that to hex to pass that as an address. I.e. \x54\x84\x04\x08

This was the most basic case of buffer overflow exploitation. With various operating systems and compiler’s protection mechanisms against buffer overflow attacks, attackers and security researchers keep coming with innovative and cutting edge techniques to bypass those mitigations and gain the maximum impact with buffer overflow attacks.
Prevention
The first step to protect your software against buffer overflow attacks is to write stable and robust code that is secure. Writing Solid Code from Microsoft is an excellent resource for writing full code.
Input Validation
The next step should be to validate all incoming inputs from the user. Various checks, such as bound checks, must be done before any other input processing. A developer should secure the software under the assumption that all user input is malicious. If the user input is larger than the stack size and the developer has not implemented any bound checks, it can result in a stack overflow.
Similarly, if the developer does not check user input and has not correctly implemented format strings, it could mean exploiting format string vulnerability. Attackers can leverage this vulnerability to ultimately compromise the software as well as the system running the program.
The first key to implementing proper input validation is to find which type of input can cause trouble. Developers, as well as attackers, use guided automatic fuzzers to automate various inputs into the application to test which class of input can cause the application to behave abnormally.
A Fuzzer generally tries a combination of various special characters, alphabets, numerals, pure binary, metadata to check if an application is vulnerable.
For more information on fuzzing, refer to OWASP’s Fuzz Vector’s resource.
Handling Strings Safely
Vulnerable implementations of strings account for the most considerable portion of buffer overflow attacks. Various unsafe functions do not use bound checking while working with strings. This results in the exploitation of the buffer overflow.
Printf, sprintf, strcat, strcpy, and gets are examples of functions responsible for these attacks. To altogether avoid overrun attacks on their production application, developers should avoid using these unsafe functions and use their safer versions, i.e., fgets, sprintf_s, strcpy_s, and strcat_s.
Developers should ensure that the destination buffer’s size is determined to ensure that function stops writing after reaching its end. Buffers should always be null-terminated even if the writing operation results in truncating some elements.
Libraries such as strsafe.h also provide safe implementations.
Maintaining Code Quality
It is common to assume that your code is safe from buffer overflow despite using the previously mentioned vulnerable functions because you control all the data passed to the functions. While this may be safe, it is not a best practice.
Supposing this code will be run for a long time, an unknowing coder may import your legacy code for their project. With this, they would also be importing your unsafe functions, which can make their program vulnerable to buffer overflow attacks. That’s why it’s essential to use safe, reliable functions.
If you need to use a vulnerable function, use it in this manner:
memset(dest, ’A’, buflen);
By adding this to your function, if someone passes the wrong length of the buffer to your function, it will cause their code to show errors. They would need to fix the issue of incorrect buffer size, and it’ll end up fixing buffer overflow vulnerability.
Using /GS in Visual C++
In Visual C++, you can use /GS as a compile-time flag. This flag enables the compiler to add stack canaries between various variables initialized on the stack. This ensures that even if your program is vulnerable to buffer overrun attacks, it won’t be exploitable.
This does not make your program completely secure, as there are indeed various ways to bypass this.
Using Stack Guard in GCC
GNU C compiler provides similar stack canary functionality under the name of stack guard, which just like /GS in visual C++ can be bypassed.
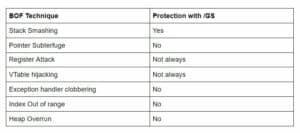
Effectiveness of /GS
There are various ways buffer overflows can modify the program execution path to their desired way, even with /GS.
Protections Provided by Operating Systems
- ASLR – Address space layout randomization
- DEP – Data Execution Prevention
These are the functionalities operating systems provide to protect applications against memory corruption exploits such as Buffer Overflows.
Source Code Audit
A source code audit is a go-to technique to ultimately ensure that there are no unsafe functions or vulnerabilities present that can lead to a buffer overflow attack.
In addition to the audit of their code, developers should also audit libraries and frameworks used by them. Every precaution in their code will render useless if the code library itself is vulnerable.
There are various tools which can help an audit, some of which are:
- Application Defense snapshot
- Flaw finder
- Rough Auditing tool for security
- Fortify Secure code Analysis
Conclusion
Buffer overflow attacks are the most common attacks, with almost 45% reported public exploits. These threats pose a significant threat to not just user applications but also operating systems.
Without security testing and code auditing to ensure the quality of code, it is impossible to prevent Buffer Overflow attacks successfully. This article has covered in detail how you can protect your application from these attacks. Code safely.






