By Matthew Butler
Computer systems are under siege 24 hours a day, day in and day out. The critical security infrastructure designed to protect those systems, won’t. The other side has the best security hardware and software systems other people’s money can buy and they have all the time in the world to find creative ways to defeat them. Meltdown and Spectre are prime examples of security vulnerabilities that have lurked dormant for decades. Or have they? If your systems are in any way connected to the outside world, the other side will get inside the wire on you. Know that going in.
Whether you write applications, libraries or work in kernel code, the line of code you write today may very well be the vulnerability someone else finds tomorrow. By nature, every code base contains hundreds of attack surfaces and it only takes one serious vulnerability to compromise your system.
In this talk we’ll see:
- How hackers think and how they identify weaknesses in our systems.
- How to identify hidden attack surfaces, attack vectors and vulnerabilities in critical systems.
- Where the most common vulnerabilities in Modern software development are and how to avoid them.
- Why common guidelines and static analysis tools often fail to find vulnerabilities.
- How to use Threat Modeling to analyze complex systems and built security into our systems at design time.
- How to use Trust Boundaries to protect critical infrastructure.
- Why open source and third-party libraries are fast becoming hidden liabilities in our software and how to protect ourselves against their vulnerabilities.
- What the best practices for protecting our code from attack are.
The critical security infrastructure designed to protect your systems is largely out of your control. The one thing you can control is the next line of code you write. This talk is for anyone writes kernel, applications, or libraries that run in the real-world and that face real-world attacks.
In today’s world, that’s all of us.
Transcription
A few year … actually, quite a long time ago in my career as a software engineer, I was put in charge of this network at a small defense contractor. When I took over the network, they actually didn’t have anything, as far as a domain controller, or any kind of perimeter security. A few months into my tour, we were penetrated by Russia and China all in the same month. Strangely enough, it was the same engineer that got has penetrated by both these countries, and so because we were a small defense contractor, I had to call the FBI both times, and the first time they were understanding.
The second time, though, not quite so much. The comment back was, “Are you trying to become the … win the award for the most penetrated small defense contractor in the US?” and my response is, “Do you have that?” I knew it the minute that I said, that that was the wrong thing to say to the FBI. They said they wanted to come and see us, and talk to us about our network. I told my boss this and he was not happy about it. He said, “We’re not having any FBI in our network.” I was like, “Well, you’ve already had Russia and China in your network. Couldn’t be any worse having our own government in there.”
My IT budget was zero. It still stayed zero, but they did at least allow me to put perimeter security in, so that I could at least defend the network with something other than harsh language, but that was back at a time when we believed, as an industry, that perimeter security was what was really going to protect us. I think in reality, what we have been doing is engaging in a great deal of overconfidence, in that we think that we’re going to take static systems and be able to defend a network from people outside who have all sorts of time and all sorts of capabilities to be able to penetrate our networks.
These are the three lies we tell ourselves, and the reason why I know about these three lies is that I’ve told myself these things over my career, is that we have firewalls. The first thing I did when I went through this was I put in a firewall. The problem is, is that every company that’s been penetrated in the last two and a half decades has had firewalls. A lot of them have had very good firewalls. The problem is, is the perimeter security won’t protect it. You have to understand that the perimeter security is going to fall at some point in time, either because the other side is better than you are at penetrating your networks than you are at defending it, or you make simple mistakes, like not patching vulnerabilities that are already in your appliances.
We tell ourselves, when it comes to code, that it’s been code reviewed, and It’s been tested. The problem is, is that most engineers are never trained in security. They don’t know how to look for vulnerabilities in code reviews. Most code reviews are line lengths and variable names. You might get a little bit, of well, you should use a different data structure or perhaps a different algorithm, but in reality, we don’t train engineers to think like security specialists. We don’t train them to think like hackers, and the same thing goes for our QE or QA, depending on what you call it.
We simply don’t train people who do our testing to think like people who penetrate systems. Then there was the one that I think my boss was coming from, is we’re too whatever to be a target. We’re too small and nobody cares. In this case, they weren’t targeting us specifically. This was a water holing attack. We’re too large. We have great security, but in reality, as large companies get penetrated because they have lots of good things to go after, small companies get penetrated because they have weak security, and everybody’s got money.
One of the easiest thing to do is to come up with an exploit, and then just run it against 10,000 companies and see who you get into. They’re not necessarily going after you specifically. You just happen to be somebody who is on their list. Who are the people that we’re out there dealing with? Well, obviously, there’s nation states, and this has been in the news for the last 10 years or so, of nation states who will go out, build zero day exploits, which they then use. They will lose containment of those exploits, and then those get picked up by the criminal element that’s out there, who then begin saying, “Wow, that’s a really great exploit. Let’s go ahead and use that.”
A lot of these things get documented, so it doesn’t stay a secret for very long. I’ve had opportunities in my past to go work for offensive organizations, but it was something I never chose to do simply because I didn’t wind … I knew the minute I created something, I was going to wind up facing the same weapons I had just created at some point in time. I’ve always played defense when it comes to network security and software security. You have the nation states creating all of the heavy weaponry, and they’re like a truck driving down the road where weapons are falling off the back of the truck.
Criminal organizations pick them up, but also corporate companies around the world who want to know either what their competitors are doing, or who want to know what perhaps a target of a takeover is doing. They will use these exact same weapons to be able to go after other companies, and Nortel networks still is sort of the epitome of the APT realm, where they were driven into bankruptcy because another company was in their network for so long, and simply kept beating them time and time, and time again, because they were reading the executives emails in real time.
The last group is actually the one that should be the surprise, but it’s actually not. Insiders are still account for most of the data losses in the world. In the news today, we have people who, whether they work for a government or they work for a company, are caught stealing information and either selling it or giving it away. In most cases, when it comes to corporations, they’re not required to divulge when they’ve been breached by their own employee, and depending on what industry, and they may be required to report it. The insider has actually become under reported. A lot more of it goes on than we really realize. The first question we have to ask is, we have some definitions as we go through this, is what is a critical system?
Obviously, a critical system is the thing that’s going to protect the data that we’re trying to protect, or is managing some environment, but it is also the unrelated systems that are connected to it. For example, printers are an easy … I went through a time when my wife called me and told me the printer was messing up. It turned out, she had been doing some research at a university, and there was nothing sketchy about it, but they had been penetrated, and someone was running a water holing attack against her that would go out and take a low priority system like a printer, replace its firmware. Now I had something inside my environment that was actually going out and trying to take documents, and exfiltrate them out of our system.
You can’t just look at the system that you care about. You have to look at all of the systems that interrelate with that particular system. When we talk about attack vectors, this is how things get done, the actual exploits that are going to be used by someone who wants to get into your system. The top two are more of a C++, so we have buffer overruns and code pointer exploits. A code pointer exploit is just simply an exploit where I’ve got some buffer and I can overrun that buffer into a function pointer that sits below it. Both of these are actually hard to find in a C++ system because they really are reliant on you not checking behavior, and we’ll look at one here in just a minute.
Undefined behavior, again, that’s also a C or C++ problem, where you have parts of the specification where they define undefined behavior, and then the compiler can do pretty much anything it wants. A lot of denial of service attacks are triggered by undefined behavior where your code is just simply correctly formed, but it does something that you’re not expecting. For privilege escalation and OWASP, so there’s the OWASP Top 10. These are just a few of the … three of the ones that are in the OWASP Top 10 SQL injection, or any kind of injection where you’re accepting input, and except you’re formatting that input in a very specific way that allows you to access things you shouldn’t, is right at the very top of the list.
SQL injection happens to be one of the top ones, and you would think after 15 years of it being number one, we would have figured this out, but we still see a lot of SQL injection out in the wild. When we talk about attack surfaces … so that was attack vectors. That’s like the disease vector. It’s like getting the flu or it’s going through the … you’re getting now the corona virus. Attack surfaces are … where do people get penetrated tends to be your face somewhere, for a lot of those diseases. Any kind of external facing interface is an attacked surface. That would be any kind of network connections, any of your authentication points, USB.
One of the favorite tricks of hackers is to go on a college campus and just drop a bunch of USBs. If you’ve ever heard of a rubber ducky, it looks like a USB, but once you plug it into a computer, it acts like a keyboard and can execute commands. You drop a bunch of USBs in the court, people get curious. “I wonder what’s on there. Maybe it’s something interesting that I would like to …” They always say, “I was trying to find the owner,” but really, what they do is they just … they’re wanting to know what’s in there. Internal interfaces, we usually ignore those because we have this belief that everything inside the wire is safe and everything outside the wire is dangerous.
We focus on the top block, but that middle block is one we sort of ignore. One of the favorite things I do when I do training for engineers, is I will have a running system and I’ll go just drop Wireshark into the environment and go listen to what they’re sending across other IPC interfaces. Those inter process communication interfaces are usually unencrypted. There’s no protection, which means I don’t really have to go get your data. I can just watch you passing it back and forth. CLIs is also another fair target for me, command line interfaces, especially if you work in hardware.
We tend to drop command line interfaces on the hardware to make it easier for our support personnel to be able to interact with the system without having to go through the front door. CLIs tend to be highly privileged parts of our system, but they also don’t come with any protection, because we sort of look at it that well, the only people who are using this are the people who should be using it, and that turns out not to be true. When we talk about security, we always talk about building in layers, or you’ll hear the terms defense in depth, where what we want is, is you start with the perimeter security, but then each layer has to have security of its own. You can’t just simply trust the layer that you’re on, that outer perimeter to be able to protect everything because it usually doesn’t.
Let’s look at some specific examples. I usually do this live, in a live situation. It doesn’t work terribly well over the internet, but this is something that is very easy to exploit. Here you have a bad copy, where we pass in a string. We’ve got a length, and this is just garden variety C code, so it should translate to lots of different languages. I have a buffer, I use a string copy, but what I’m not doing here is I’m not checking to make sure that the buffer that I’m having copying from is either the same size or less than the buffer that I’m copying into. This is a very simple mistake. This kind of code shows up all the time, when you have people who are … they’ll put code out on the internet and they’ll say, “Error checking removed for clarity.”
Well, that’s actually kind of the code you see a lot in production, is where there really isn’t any error checking. The strategy behind a buffer overflow, is simply that I’m going to call a shell. That will allow me to call a shell using your privileges. I won’t go through this exact code. There’s lots of examples that you can download and look at, but if you look at the memory in an x86 architecture, at the bottom end of the memory, you have the data, which is where the programs all run. At the top part, you’ve got the kernel. The stack starts at the top and grows down on, and the heap starts in the bottom and grows up. What I’ve done is I’ve taken one stack frame and I’ve actually pulled it out so that you can see it, so you have a buffer.
You’ve got to return pointer, which actually points back to the calling function where it was called from. What we want to do is, we want to override that return value with something that points back to a different spot. What you do is you put together a little payload, and these hex 90s are nothing, what we call a NOP sled. What happens is that I want to overwrite that return to point back into my NOP sled. It’s going to hit those hex 90s and then it’s going to get down near the bottom, where you’re suddenly going to wind up seeing an address. That address is going to point you somewhere else into system memory. In this case, it’s just going to run your little script, which takes …
If you have a buffer overflow into something that’s running as root, or is running in admin, now all of a sudden, you’ve got the ability that your shell is now running with the credentials of an admin. That’s a very simple example. One of the things that we’ve done to protect that is ASLR, address space layout randomization. What this does is, this takes a lot of the programs where you might want to execute things in a particular program, certain libraries, and it begins to move it around. The program and the libraries are all moved around each time you bring the system up. This makes it very hard to calculate offsets, to be able to run a particular exploit.
In this case, it makes it more difficult, but there are ways around it. It’s automatic by the OS. It’s not something that you have to worry about, but there are ways to get around this. It just makes things a little more difficult, and that’s really the theme for security is, there is no place that you can call secure. You can’t go in one day to your boss and say, “Okay, we are totally secure.” That actually does not exist. What you can say is, is we are more secure than we were last time because we did something and this is one of the things we did to make it more secure. The nature of security is such that you want to raise the bar high enough, not so that you’re absolutely secure, because you’ll never get there, but it’s you’re more secure than the person next to you.
Then whoever’s coming after you is going to say, “Well, this is a little more difficult than I want to go into, so I’m going to go to the person next door,” because hackers, in many ways, are rather lazy. They’re opportunists, and they want to go after the easy operant marks, and not waste their time on the people who are more difficult. Stack canaries is another way of doing this. Most languages have this built in, so it’s a value that … if that value gets changed, right before you hit the return call, it knows that you’re trying to run this kind of exploit. You can guess these. They can be leaked. You can figure these out, but so it’s also not foolproof, but again, it’s just a matter of raising the bar a little higher.
The first best practice is maintain situational awareness. Know who you’re talking to, and know that the data that they’re giving you may not be formatted properly. It may not be the right data. If you’re not validating the data and you’re not verifying who you’re talking to, then you’re not maintaining situational awareness. That’s the first step of getting burned. Here’s another vulnerability. This comes from C++. This is an enumeration. Almost every language has some sort of enumeration here. You’re taking an integer value, and you’re just casting it into this enumeration. The problem here is with this line, because you’re not bothering to range check this, and in C++ … Specifically, in C++ 14, if you did this, and that number was out of the range, it becomes unspecified value, but in C++ 17, we change this so that it becomes undefined behavior.
I mentioned that before. The standard has made a change that, while it sounds very subtle, actually has pretty serious implications because unspecified value just means you now have a value that’s out of range, and otherwise things will work out fine for you. The problem here is now you’ve undefined behavior in the compiler can do pretty much anything at once, including optimizing things away. Now your system is not built. The compiled binaries don’t actually look the way you’re expecting them to in your code. What we did was we came back and we added strongly typed enumerations. This is one of the ways to do this. Now you have the class keyword up there, which makes it strongly typed, and this now handles it for you under the hood.
The second best practice is to study the standard, especially in languages they’re complicated. The nature of languages is such that when a language first comes out, it’s always very simple. They always make the claim that, hey, this is a very simple language. Java was this way. Rust is this way. Go is this way, but when you get 20 years in with a language, you find out that we’ve added a lot of surface complexity. C++ is a perfect example of a language that has an enormous amount of surface complexity to the language, but started out actually fairly small, and I know this because I started out with C++ 1.0 back in 1990. That was a very simple, straightforward language.
Now it is a horribly complicated language, even for someone like me who’s on the Standards Committee. Warnings. A lot of times, I see companies ship software that have 10,000 warnings in them, and if it’s a large enough code base, they’ll have 5000 warnings. In the end, what I always tell people is in the same way that pain in our bodies tells us something is broken, warnings in our code tells us something is inconsistent. That’s the compiler trying to tell you that it can compile your code, it can get you a binary, but it doesn’t make any sense. These become future bugs.
One of the campaigns that I have a lot of companies going on is, is that every time you do a commit, you have to lower the warning count. You have to lower it, unless you absolutely know that warning can hurt you and you don’t want to turn that off for other reasons. In some language, you can turn a warning off. In this instance, it may make sense, but in another instance, you may want to leave that warning on. In this case, if you have warnings and you’re ignoring those warnings, you need to begin turning those warnings on, and either turn them on as where warnings are errors, and force yourself to deal with them, or begin bringing that backlog down, because those warnings are trying to tell you that something’s wrong in your system, and that it’s inconsistent.
The third best practice is, warnings or errors, because they are. They’re future errors, but they’re errors nonetheless. This is another exploit, and this was sort of a really interesting one. Dirty Cow, and I put the CVE number in there so you can go look up more on it, Dirty Cow was first introduced in 2007. It was actually a fix. It was fixed earlier than that, then it was broken by another fix, and then it was … in 2007, and then they found it again in 2016 and fixed it, and the fix is actually quite small, but in this case, it’s down in the kernel, which means that it is something that everybody’s going to hit. No matter where that kernel gets released, it was going to be in there.
It was in there for about nine years and we do know it was actively exploited. It’s a vulnerability in the copy on write, which I’ll go through the Linux version of copy on write, but every operating system in the world uses a copy on write because, if, for example, you’re writing to a hard drive, you don’t want to write to the hard drive, have that process write to the hard drive. Each time, you want to be able to write to a file or write to somewhere in memory, and then have the operating system handle that in the background. Again, this is one of the ones that I do live. It’s actually very simple to do. Here we have, basically, a copy on write.
We’re reading from the file system, but when we write, we’re actually writing to a copy, that that copy will actually be written out to the file. A of that’s just performance. This is from Linux, so it creates a memory map. What we’re doing is, we’re creating … the map private creates the copy on write. We have a file descriptor to the file that we want to write to. This code goes in and actually accesses the memory, and we’re going to write our payload out to the memory. Then we have what’s known as madvise. Madvise is a way in the system to say, “We don’t need this. We’ve written to this copy, but we’ve decided to throw it away.”
In this case, maybe we’re writing to a system file, and we’ve decided we were not going to write to it, either because we don’t have the privileges, or we’re going to not write to it because we’ve decided to abandon the changes. There’s the process in the right hand side as to how this works. You write to it, it sets the dirty bit. Once you do the madvise, it throws it away, and then it rereads the file so that memory is refreshed, but in that case, there’s an opportunity for us to go and trip this up, because there was a vulnerability in here where if you would run madvise over and over, and over again, at the same time you’re trying to write, it would allow you to write to a system protected …
It would allow someone who doesn’t have root to be able to write to a root file system. For example, let’s say we would want to go in and replace ping, so that we could actually replace the application. Or another case, you want to go in and change … enter the password file, which you should not be able to write if you don’t have root, be able to change yourself over so that you can change it to a give yourself root access. This takes seconds to do. It was actually a very simple vulnerability. I don’t have the code to show you here, mainly because the code for this one function would not even fit on one slide, even if I brought it down to the lowest font I have, and that is part of the problem.
You have a very simple exploit. I’m going to open the password file. I’m going to go to the place where I need … I’m setting up my private mapping. I’m going to go to the place in where … I’m going to find the place where I want to begin making the changes, and then I’m going to spin up these two threads, one that opens it and makes the change, and the other one keeps calling madvise. That’s the bug. You can read a lot more detail on this in what I gave you, the CVE number, and this was actually created by the creator of Linux himself. Linus himself was the one who created this bug while he was trying to fix another one. It’s mostly bad news on the countermeasures here, simply because none of the upstream reviewers found it.
There were no forensics to know this is going on. Other than the code change, there was no counter. There was nothing that you were going to be able to do to protect it. This just sat out there latently until somebody found it. Dynamic analysis is one of the things we’ll talk about a minute, that might actually have helped this. Code reviews, we’re unlikely to get this simply because it’s very hard to find race conditions in a code review. You either have to really know the code and just catch it as you’re going through it. Or you have to be able to run this live and be able to do these kinds of tests. This goes back to what I said earlier about, we don’t train testers how to be pen testers, and in many ways, we train pen testers how to test code at that level.
We train our pen testers to be more, “How do I get in from the outside? What kind of things do I look for?” The more OWASP Top 10, but if you’re looking at something down in the operating system, it can be very difficult for even a pen tester to find them. Complexity is the enemy. If you go look at this code, and I really would suggest that you do, this is a very long function. It’s hundreds of lines long, and this is a very complex part of the system, which is probably why Linus was the one working on it. In our industry, we sort of have this love of complexity. There is a part of us that feels good when we create something that is very complex.
The problem that we find in complexity is that one, it makes it far more difficult for the person who follows you to be able to understand what you’re doing, but it also makes it hard for yourself. Again, the Dirty Cow, was a problem that was introduced by another fix, by the person who had actually written this particular subsystem themselves. He had a very complicated piece of code that he came back to. He wrote in a fix, which actually created this break that stayed there for nine years. It was the complexity that worked against him. I mean, Linus isn’t a very smart person. There’s no problem there. It’s not like he was a junior software engineer.
He’s somebody who has a great deal of experience designing operating systems, and certainly designed this piece, and should have understood this, but because this is such a highly complex piece of the operating system, what he didn’t see in there was that he had made a mistake that was sort of now hidden by the complexity. We’ll talk a little bit more about that here later. What do I look for when I look for … when I go into a system? When I’m looking at your code, especially if it’s a code that allows you to do raw memory addressing, I look at anytime you copy your move code, because you’re likely to get this wrong. That’s not just being able, like in C or C++, being able to use pointers. That’s anytime that you’re using indexes, to see if you’re using … if I’m off by one bug.
Anytime you’re using an iterator, there are … I’m not sure if every language that has iterators, if you can invalidate an iterator, but certainly in C++, it’s possible to invalidate an iterator. I look at anytime you’re touching memory, to see in my code view, to see whether or not you’re making a fundamental mistake there, I look for all the places where you don’t validate your data or verify who I am, because I can send you anything and you’ll choke on it. The denial of service attacks are nothing more than me sending you data, you accepting it, and you trying to process it, and you have no idea who I am. I could be anybody.
The third thing I look at is the open source libraries that you’re using, because their vulnerabilities and weaknesses become your vulnerabilities and weaknesses. We’ve had a number of cases, of instances where people have gotten control of a third party library. Now all of a sudden, they’ve turned it into a bit mining operation. Nobody really knew about it because they just accepted that that library … they’ve been using it for so long, they never really thought about that library being compromised. We’re beginning to see more and more what we call supply chain compromises, where we’re beginning to see people being able to get in, be able to put in malicious code.
Millions of people download it and use it, and now all of a sudden, you’ve got your own system being used as a platform that people can use for attacking other systems. Internal interfaces, when I want to penetrate a system, the first thing I’ll look at is, are you guarding your IPC interfaces? Do you have command line utilities? Because command line utilities are going to be completely unprotected. That’s just a binary. I run it and if I don’t give it any parameters, it’ll tell me what the parameter list is. Now I’ve got full access to your system, once I’m on that box, and then your IPC interfaces are wide open, so I just Wireshark them.
Any place I find complexities errors on, because that’s where you’re going to have problems. If I find complexity in there, I know that you will have caught the bugs in the simpler pieces, and so that’s where I go after it, because I know all of your really hard bugs are in there. That’s an opportunity for me, and then any place you spill secrets. This includes keys that you burn into your binaries. I know we all talk about safety and we all want to do encryption, but a lot of times, engineers, they haven’t really thought all the way through to having a key store, so now they’re … and I have engineers calling every two weeks before their release and say, “Well, is it okay if I put the shared secret in the binary? I was like, “No, it’s not okay. It’s a security vulnerability. Here’s how I exploit it.”
I’ll actually take a stringified program go run it against their binaries and tell them what their shared secret was, because usually they’ve done it before they come to me. They just want me to sign off and make them feel better about it. Anytime you write privileged information into a log, or into an error, that’s an opportunity for me to learn something about your system, even if it’s debug mode. A lot of times engineers say, “Well, we’re writing this in there because we need debug analysis,” but so many times, systems will ship with the debug actually turned on because somebody forgot to turn it off when it went out the door.
Don’t do that, even if you’re just doing in debug mode. If you have privileged information, and if you’ve taken the time to use encrypted at rest, and you’ve got that protected, don’t undo the protection by writing it into a log. My advice to companies is to grow bug bounty hunters, simply because you want people who know how to go look for vulnerabilities in software. I’m not talking about at the pen test level. That’s very high. Or even at the QE, because they’re looking word functional and regression bugs. I’m talking about people who know how to actually go find hard bugs in the system. When you grow bug bounty hunters like that, start a program that rewards them from it.
When you find somebody who has actually created or found a bug, that could be an exploitable vulnerability, reward them financially for that. You are saving your company so much money because it’s better that they find it, than somebody on the outside does. No, this is not bug bounty hunting. This is one of my favorite cartoons and I have it on my wall. You create the bug, you find the bug, you fix the bug. You’ve already paid to write the code correctly first time, so writing bugs that define them, that’s not bug bounty hunting. Sun Tzu said that all battles are won and lost before they are ever fought, and this is where this is the before they’re ever fought, once you’re out in the wild, that’s the point at which the battle begins, but here’s the before part.
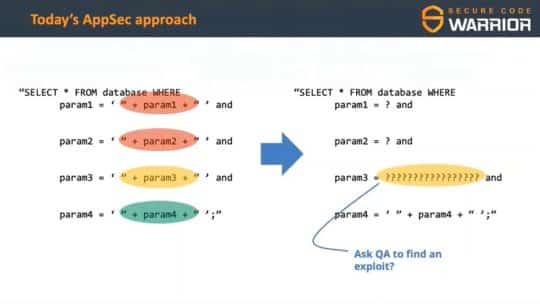
If you have a language, if you use a language where you have a static analysis, tooling. Static analysis just looks for things like code and API mistakes. It’s an automated way of just going and finding in C++ one thing you might have is, is don’t use string copy. Use string and copy. Well, if you go back in this video, you’ll find that I actually used string and copy, and that would not have been caught by most static analyzers. Part of the problem, though, with that is you tend to get a lot of false positives. They’re only as good as their rules. They’re not a silver bullet. They’re just one layer of protection.
This is a way for you to backup your engineers to be able to find some of these easier bugs that are rules based, things that we know have been done in the past. Places where, perhaps, you’re not checking, you have off by one errors, or you’ve got a unbounded, where you’re doing unbounded memory accesses and things like that. These are really best for simple coding and API mistakes. They are not the silver bullet. I’ve given talks and people say, “Yeah, this one will catch that and this won’t catch that.” Then I go and actually run the system they’re talking about, and they find out, none of the vulnerabilities that I brought up were ones that would have been caught.
Dynamic analysis tools, these are specifically designed to run in your code at runtime, looking for things that you might not be able to catch just in your own code reviews. This is purely for the runtime environment, and where these really stand up and shine … I don’t have tooling for every language out there. These are mainly for C++, but where these really shine is in performance stress and scalability labs. If you don’t have a performance stress and scalability lab, I really highly recommend you put one in. That is where it’s a totally separate lab, where every time you cut a new build on some schedule, you’re going to go put that in there, and you’re going to run your software 24 hours a day, seven days a week, because that allows you … and you turn these tools on, which allows you to look for those hard bugs.
There’s different approaches. One, you’re scaling up. Two, you’re running long term. That’s why it’s called a performance stress to scalability lab. There’s really three types of tests that you want to run against this, but allows you to do that long term testing where you’re soaking the software and catch these bugs early. Don’t wait for a release candidate. Start doing this as you’re getting your developer builds out, once you’ve got some confidence in the features, that they’re actually fairly stable. Fuzz testing is a huge tool for people to use. If you are talking about interfaces that talk to the outside, you want to fuzz test these.
This gets back to me handing you garbage data and making a choke on it. You want to be able to go ahead and fuzz those interfaces, pass them … And this is not just sending them totally random data. A lot of these fuzzers use genetic algorithms or they use … or in one case, it’s coverage guided fuzzing. What they do is, they actually learn by the responses that come back. This is where you’re going in and you’re actually trying to break the interface where you’re not checking and validating the data that’s coming in, that you’re actually chewing on.
Penetration testing. This is probably the hardest thing for people to do simply because most of us don’t think like hackers. If you’ve been Doing it long enough, you’ll know there’s a mindset, and one of the reasons why I use this character in the background here is, to me, it’s a joke. Hackers are not demigods. They are not these brilliant engineers, but for having gotten on the wrong side of the tracks, that they would have been the next brilliant software engineer. These are people who, in many ways, they’re lazy in many ways they just are defective in some way. They breaking things and harming people, instead of actually doing what we do, which is create systems that help people.
But that whole wearing a hood, sitting in front of a green screen at night, that’s completely idiotic. That is nothing more than Hollywood. That’s why I use this character that’s in the background on the cover screen, is because that’s just a Hollywood manifestation. That’s not what hackers are like. Hackers look just like us. If you go to DEF CON, or you go to Black Hat, you will see a lot of people and most of them are going to be hackers and the other half is going to be engineers, and they’re all going to look a lot alike. This idea that there’s somehow these gods, it isn’t … what it is, is while we were thinking about writing elegant algorithms, or we were thinking about data structures, or we’re thinking about how to build a system, they’re out thinking about how to penetrate into a system.
Here’s some of the tools of the trade. Metasploits are very good. It’s an open source pen testing framework for going into a network from the outside, looking for vulnerabilities that are already there, coming up with your own vulnerabilities. Nmap allows you to go and do attack surface mapping. You can use that by going and looking, and seeing who’s talking on one port, on a particular box. I use that quite a bit when I want to penetrate into a system. Burp suitem or ZAP. Burp Suite can be expensive, so ZAP is the freeware version of it, and it’s they’re … They’re both very good. If you’re doing web security, these are good options for you to use to do your website testing.
They are like sort of Metasploit, but for websites. Python is a great scripting language when you need write something very quickly, that allows you to go just penetrate into a system. Then I’ve mentioned Wireshark. RawCap is the sniffing the loopback adapter. John the Ripper is for passwords, and then Strings, which is … because developers love security through obscurity, we like to bake things in and going and getting Strings pulled down is very easy and very helpful. Other options are you can go out of house. Most of the companies that I work for have some external pen testing company that comes in and helps them, but it is always better if you can grow this internally, because these are people who know where all the bodies are buried in your software.
This is a chart I put together is just how I do all these things. We’re going to talk about threat modeling here in a minute, but as you go through your development process, there are things you want to be able to do at different stages. This is just the chart that I operate off of, is where we begin to do these different types of testing. It’s important to do all of them, simply because they all go after a different place in your software, and they go after different types of vulnerabilities. All testing is asymmetrical. There isn’t going to be one silver bullet. There’s no way that if you do just one of these things, you’re going to really raise the bar that much. It’s these things working in concert.
Threat hunting is about understanding the nature of the threats. Fortunately, we’re used to doing this. If you’ve ever gone to a city that you’re not used to going to … I was in China last year and I didn’t feel particularly threatened. It was just I was in a place where I didn’t speak the language. I didn’t know anybody, and walking around the streets, you’re really not sure of what the rules are, because it’s a very different country than the one that I’m in. Things like darkness, isolation and security and vulnerability, those are things that we’re used to dealing with.
Well, that is how you do threat modeling, but we also need to understand the nature of the people who will be attacking our systems. This is an intrusion kill chain. I’m not going to go greatly in depth to this, but this is really the playbook of how an attack will progress. This comes from Lockheed Martin, and it’s very good. You should go and read up more on this, but these are the seven steps of reconnaissance, weaponization, delivery, exploitation, installation, command and control, and action on objectives. The first three, you’ll probably never see until after they get to step four, and then by the time they’re on step six, they’ve pretty much got everything that they need.
The threat modeling stage is … threat modeling is a fairly intensive process. The first thing you have to do is, is define the scope. I have my system. There are some pieces that I want to look at early, some pieces I feel like I can wait till later. If you wind up narrowing in too much, you’re going to miss threats. If you go too broad, you’re just going to be drowning in information. The first step is to create the scope, then you create a model of, and this is where it doesn’t work that well with Agile because Agile is really not something that lends itself to heavy documentation, but threat modeling does require a lot of documentation.
Then identifying where the trust boundaries are. Where are we holding data we don’t need? Where are we allowing access we shouldn’t? Then you’re going to classify the threats. Then you have to go in and say, “Okay, once we’ve found a threat, what are we going to do about that threat? Then what are we going to do to validate that? Again, this goes back to the Dirty Co and why I’ve put it in there. There was no validation step. I fixed this one issue, but I didn’t go back to find out if I had fixed another issue, or actually broken the other issue. The first thing we want to look at is trust boundaries. Different levels of trust carry different risks.
When we have looked at trust boundaries before, we’ve said, “Well, everything inside the wire is safe. Everything outside the wire is unsafe,” but the new normal of the way we look at it, is we assume the perimeter security is going to be penetrated. We have to look at where does our data cross from one level of trust into another? Where is it that we’re crossing from areas where we have control of the security, where areas where we don’t? In Stride, this is the model we’ll go through today, we have spoofing, tampering, repudiation, information disclosure, denial of service and elevation of privilege.
Spoofing is just where we’re masquerading as someone else. Tampering is just straight up sabotage. Repudiation is where I can act in your system, but you don’t have any evidence of action. That’s where logging comes in. Exfiltration is getting the data, the information just goes there. That’s just exfiltrating the data out of the system. Rendering sub system unusable is denial of service, and then gaining elevated privilege, that’s just a straight up privilege escalation. Here we have just a basic system. This is a remote DVR system. It’s pretty generic. There’s nothing really different about it. There’s no tricks or hidden traps, but if we were to look at our traditional view of where our trust boundaries are, we would look at places that are marked in red, which is the places where you going across the network.
Basically, anytime you go off box, you now have a trust issue, so you have a trust boundary that you have to deal with, but in reality, the way it works today is we have to assume that people are going to get on the box, which means you now have to deal with what’s local. You have a data store that can’t just trust any process that has to talk to it. That includes the upload download process at the bottom and the center, or the AV process at the top. You can’t trust the web servers, even if that web server is actually sitting on the same box. You have to assume that if that’s penetrated, you need another layer between you and the data store.
The new normal of where we’re changing our minds on trust is we’re talking about this concept of zero trust environments, and that is that whoever you’re talking to, they have to authenticate. You have to validate and verify who you’re doing business with. We’re going to look at one, just information disclosure, and think for a minute as you look at this diagram, where are the potential places where we could have information disclosure? The obvious places are going to be the data store. That’s where the date is. it seems reasonable that that’s going to be a place where we’d have information disclosure, but there are others.
If you look at the diagram and look at other areas of it, for example, the static content also has the potential for information disclosure, because that tells you something about how the system works. The web servers themselves can disclose information because what you have in those is you you’re now maintaining state, and you may be maintaining cookies, or you may be maintaining other artifacts, that if I can get in and get those, now I know how the system is working. It allows me to go in and penetrate that system more deeply. It’s not enough, when we talk about information disclosure, to look at where the data is. You have to look at anything that accesses that data, that you can reach.
The takeaways from … and we won’t do all them, because this is actually a very long process to go through all of these. Zero trust environments, the reality is there are no safe spaces, or trusted environments. You have to assume that they’re going to get inside and onto the box that you’re operating on. Exfiltration is becoming as important as infiltration. I think, in many ways, we feel like we’ve lost the battle of infiltration. Now we have to think about exfiltration as well. Complexity is the enemy. I say this a lot, but it takes a long time to sink in because complexity produces emergent behavior. It’s very hard to reason about a complex system.
The more simple your system becomes, the easier it is for you to reason about and know how it’s going to operate. Then threat modeling is more than just about modeling threats. It exposes that emergent behavior and allows people to know the system from end to end. A lot of times, I’ll hear people saying things like, “Well, I didn’t realize that’s how that worked,” or, “I didn’t realize we were holding that data. Why are we holding that data? We don’t even use it anymore.” Threat modeling is one of those things. It’s like an architectural analysis, which exposes things in your system that you don’t expect.
Security and layers, again, this is defense in depth. Use the principle of least privilege. We have these patterns of the way we do security and it tends to become repetitive because we say it over and over again, but I see so many times that they get violated, but we have these patterns because we know they work. If you’re using the minimum amount of privileges necessary, it makes it much harder to penetrate a system. You want to grant and revoke privileges as you need them, not just have them on the whole time. Then again, complexity is the enemy. It’s very hard to reason about your code. It’s very difficult for other people to understand your code as its complexity increases.
Logging is one of the first places I go, is I go grab the binaries and I go grab the logs, because this will tell you a lot about how this works. One of the things that … if you are seeing your system fail, make sure that one of the things you’re doing is you’re logging any exceptions, you’re logging any segmentation faults, because in the same way that we saw that there was that … back when I was showing you the hex 90 sled, you will see artifacts in the memory that will give you an idea of what people are doing. Your memory may be getting corrupted in a very specific pattern that tells you what’s going on.
We don’t encrypt our logs. They’re always a very good source of information, but one of the things that you want to do is make sure that you sanitize what you put into them. Again, if you’ve taken the time to encrypt information because it’s critical, don’t then turn around and put it in the log. That defeats the whole purpose. Then using audit trails for security becomes ultimately very important simply because you want to make sure that you know what’s going on in your system, and that’s that non repudiation piece that we went through. Secure coding starts with secure designs. One of the things you want to make sure that you’re doing is that you’re paying attention at design time. And that you are absolutely paying attention to security as you design the system, not just on the other end, when it’s being pen tested.
Code reviews, one of the things that I always tell people is when you’re doing a code review, is make sure you code review the feature, not just the change. Again, this was the problem that Linus got into with the Dirty Cow vulnerability, was that he code reviewed the change, but not the feature itself. Did he go back and expand out and make sure that he understood all the implications of that? That’s happened to me. It’s happened to millions of developers. Ruthlessness is a virtue, not in that you’re going in and you’re looking to make somebody look, bad but that you’re going in to really find those hard bugs.
Nobody likes working in legacy code. I get that. I work in it and don’t like it that much either, but it is something that you wind up having to … That’s going to have your worst vulnerabilities because it’s the thing that’s in the rear view mirror. Today’s code becomes tomorrow’s legacy code, so if you’ve missed something today, that’s now something that’s in the back that you’re not even thinking about. This copy on write bug for Dirty Cow was a legacy code bug. Ruthlessness in your code reviews. Again, this isn’t about making colleagues look bad. This is just simply about making sure that you are looking for the hard bugs in your code reviews. You’re not just saying, “I don’t like your line lengths or your variable names.”
This is becoming a bigger problem, libraries that we don’t write, that we’re using. They’re becoming ubiquitous. We are finding example after example, especially over the last few years, where people are going in, and this is both in JavaScript libraries and libraries in C++, or Python, that have been penetrated into, where we are finding libraries that wind up … their vulnerabilities become ours. Try and limit your use of open source. Most libraries will never be reviewed for security, so that’s sort of on you. One of the techniques you can do, besides going into the library and actually looking at the code, is to go drop it and start using it. Look for spurious emissions.
If you’ve got a library that doesn’t have anything to do with the internet, but you see it opening up sockets, you have to ask the question, why are they opening up sockets? Then this is the old maxim of ‘trust, but verify’ with code reviews. Make sure that you’re not just assuming that that’s been code reviewed, because I can almost guarantee you that it is not. Remember that you’re only as strong as your weakest third party library. That’s become the Trojan horse. When we do supply chain hacks, that’s a great place to do it, because it’s the place we, as developers, don’t expect.
Question: You have 10 best practices. Is there one that’s more important than the rest? Or do you think they’re all equal?
Matthew Butler:
I think they’re all 10 best practices important because they’re 10 best practices that I’ve learned the hard way at one point in time or another my career, but if I had to pick one, the absolutely top one is complexity is the enemy. If you do nothing more than cut down the complexity, and if you increase the simplicity of your system, and the way you do systems design, the way you write your code, you will make it possible for you to catch a lot of those really hard bugs that you would ordinarily not catch.
One of the other things that … one of the areas that I work in is actually in safety critical, and one of the things we know about us, that includes airplanes, the way that metal stresses as you have constant pressure and depressurization, is that … The metal skin of an aircraft, as it expands and contracts, they will develop weaknesses in the metal and the energy will begin to collect on those weaknesses. The same thing happens with vulnerabilities. If you have vulnerabilities, they’re going to migrate to the areas of greatest complexity, not because they’re moving, but because you’re catching all of the ones in the simple areas.
Simplicity is something you actually have to practice. It’s not something that we’re trained to do, but if you will get into the habit of actually practice coming up Occam’s Razor, the simplest solution, all other things giving equal, is usually the right one. If you do nothing more than work on the complexity of your systems, on the complexity of your code, you will make a huge difference in your ability to uncover bugs before they go out the door. That would be my number one.
Question: What if you don’t have a test program, where do you start?
Matthew Butler:
Earlier, I showed you that diagram where it has all of these different testing steps and different testing strategies, and I said they all work together, They do. The problem is, is if you’re starting from zero, you can’t go from zero to having all of these in place, at least not doing them all credibly. The first thing you have to do is go and look at where are you? Do truly have nothing? Or do you just not have the system geared towards doing these kinds of testing, whether it’s static, dynamic fuzz testing, penetration testing or threat modeling?
The first step is, understand that some of these are going to take a long time to set up. Threat modeling takes a long time. You usually need to bring someone in to teach you how to do threat modeling, because it’s not something that’s easily learned. It does require doing a lot of documentation. What my advice to companies is, start somewhere. Don’t feel like you have to try and take this whole thing on at one time, because if you try and do everything at one time, it will be very difficult for your engineers to actually absorb all of that.
Start with something simple. Go find a tool that does static analysis. Go teach your engineers how to do proper code reviews. Bring somebody in who’s trained on the language you use, have them train your engineers on how to do proper code reviews. Start somewhere. What happens is, if you look at this whole thing and you think, “Okay, this is just too much,” you won’t do anything. The best thing is to just pick one piece, go and learn about it, implement it, and once you feel like you’ve got that under your belt, then go on to the next ones.
Question: Are you saying we shouldn’t use open source libraries? How does that work?
Matthew Butler:
It’s very difficult, in this day and age, to get along without open source libraries because in any fairly large project, you’ll use thousands of open source libraries. What you have to understand, though, is that the onus is on you to ensure that the pedigree of that library, you know whether or not it’s been tested for security, whether it’s got an ongoing test for security… No, I’m not saying don’t use them. I’m just saying you have to understand the risk. One of the things I would do would invest in a system that will allow you to go out, look at the third party libraries, tell you which ones have vulnerabilities, and that gives you some idea of what threats you already have, and what your exposure is at this particular point.
The point I’m making when I talk about third party libraries and preferring some libraries over another is you have to understand, you now own that library because it’s in your product. When it fails in your product, it won’t be good enough for you to go and say, “Well, this third party library was the problem.” Your customers will come back to you as the person who created the problem for them. One of the things we’ve haven’t done a very good job as an industry, is taking ownership of those third party libraries and making sure that when they’re in our product, they become something that we’re now responsible for.
We need to know what the pedigree of them is. In two instances that I know of last year, one of them turned to … it was a JavaScript library into a … or I think it was a Node.js, turned it into a Bitcoin mining. In another case, we had two Python libraries that had very subtly different names, that people were downloading and using, that did what they were supposed to do, but they were also scraping SSL credentials, and GPG credentials, and then sending those out. You need to take ownership of the libraries you’re using, not just, “Should we use it or should we not use it?” But also look at what is it doing, and is it doing what we think it should? Or is it doing some other things that we know it shouldn’t?