
Agile software development. It’s a buzzword that every company seems to be using at every possible opportunity. The idea behind the concept is simple: ship fast and ship often. While this may seem like a good idea when you’re trying to reduce the feedback loop time for user experience enhancements, new product placements, upsell experiments, and general marketing initiatives, how is agile really impacting your code’s security and robustness in the long run?
A major issue that developers face when it comes to software development is working out the balance between getting the code right versus shipping out working code. While these two things may sound the same, the delivered product and its quality can vary by several miles. Working code might not necessarily mean that it is secure in design, architecturally sturdy, or have gone through all the checks and tests to assure your software and applications are secured against data leaks.
In this piece, we explore the different potential vulnerabilities that agile software development can create and how to solve them with code pipelines.
Breaking Down the Issues of Agile Software Development
The idea of agile is synonymous with speed, but how quickly can you ship out code before it turns brittle and breaks into a million little dependencies? When developers are short for time, shortcuts are often taken just to get things to work, which can look like this:
- Overrides and global namespace pollutions
- Unrefactored code glued together with adapter and transitional patterns
- Discarded code in favor of new modules rather than repurposing or updating what was created a few sprints ago
- General code pollution and lack of cohesive general structures
- Slash and burn code mentality where old code is instantly regarded as legacy without proper assessment and care during extensions and adaptation processes
Why are these things a problem? Because they are the precursor for the eventual slide into spaghetti code. Getting product shipped usually comes with time constraints. When the pressure to deliver is too high compared with the size of the expected deliverable, shortcuts will be taken.
Product managers know this and may promise us extra time after, but if there is no time to get it right in the first deliverable, there won’t be time to fix it at a later date. When it comes to agile software development, everything else is not a priority except for the thing you’re currently working on. The tickets will always keep coming and there will never be a pocket of time where you can look back, assess, and refactor as necessary.
So how can you fix the issues caused by a lack of time? The quick answer is in the pipelines and processes.
The Upfront Time Investment Required to Ensure Long Term Security Implementations
Your automated processes and pipelines can make or break your code. Not having one at all is an ingredient for the long-term accumulation of bad code. A pipeline can be as simple as setting up a process where code can be reviewed and peer tested before it goes through a series of automated checks.
One way to do this is to implement this through a service provided by AWS called CodePipeline.
Implementing AWS CodePipeline 101
CodePipeline is a service by Amazon Web Services that lets you automate and continuously deliver your code without having to manually push, merge, and test everything. This means that once you finish coding your part of the sprint ticket, the pipeline handles the integration and delivery of the feature, enhancement, or bug fix through an automated process.
So how do you implement CodePipeline?
1.Start by going to your AWS console and search for CodePipeline in the search bar if you don’t already have it as a shortcut.
2.Select CodePipeline.
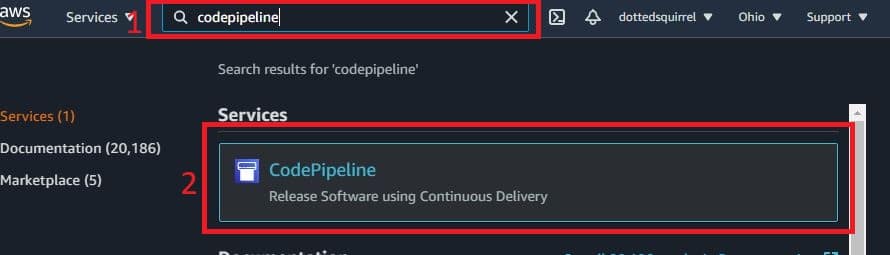
3. The console shows you a list of pipelines that you may already have. If not, you are given an empty console. Select Create pipeline to begin.
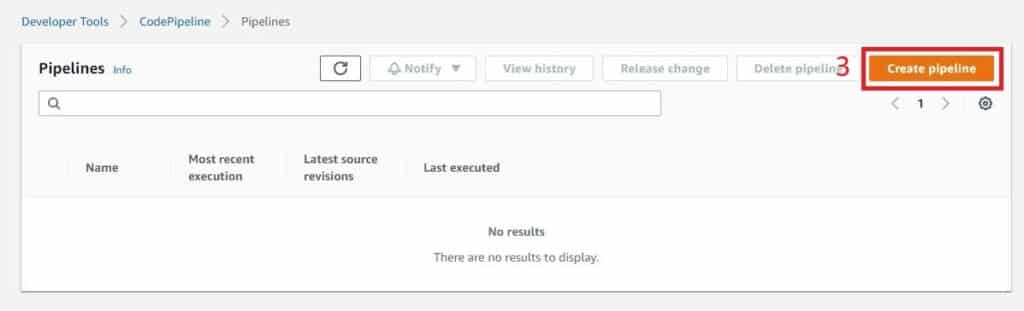
- Give your pipeline a name. If this is your first pipeline, the name should describe the process you’re trying to implement. Avoid naming pipelines after specific features. Rather, name it so that it describes that application you’re targeting and the process you are working on automating. Here I’ve named it ShoppingCartWebApplication.
- Once you’re done, select Next.
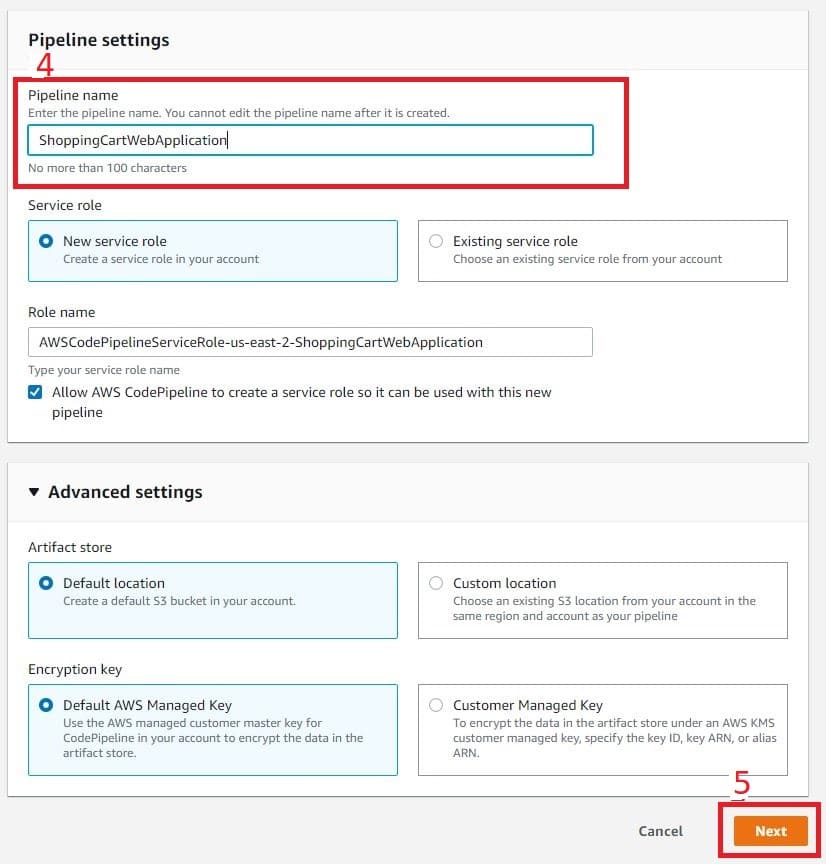
- Next, add a source. Multiple sources are available, including AWS CodeCommit, AWS ECR, Amazon S3, Bitbucket, GitHub (version 1), Github (version 2) and GitHub Enterprise Server. For this example, I’ll be using GitHub (Version 2).
The main difference between GitHub (Version 1) and GitHub (Version 2) is the way authentication and authorization are performed. Version 1 has fewer checks on it. Version 2 requires more authentication, naming, and handshaking before you can connect with your repo. From a security stance, Version 2 is more robust.
- Once you’ve selected GitHub (Version 2), click Connect to GitHub.
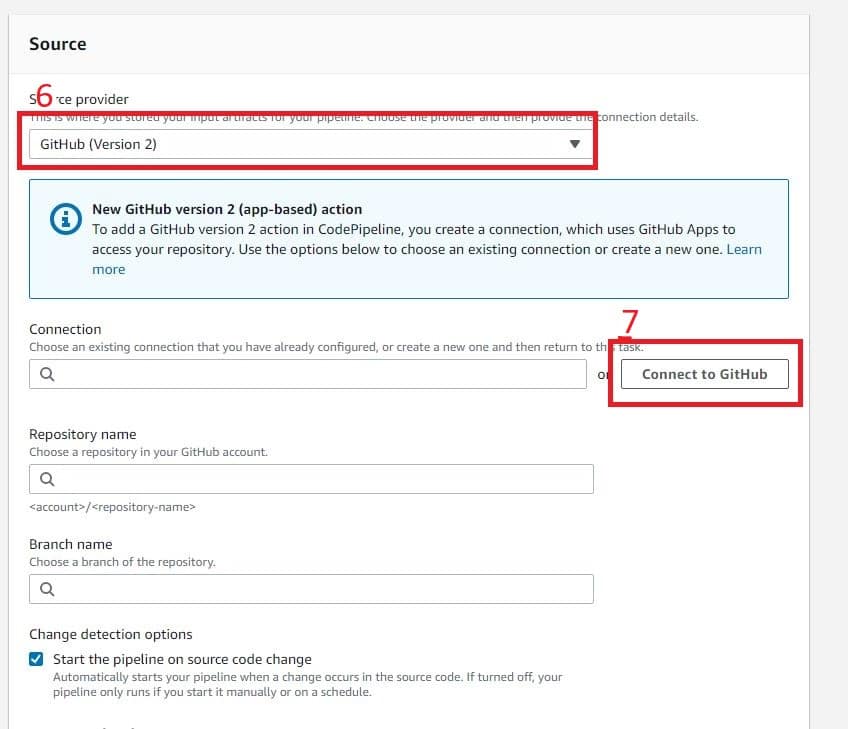
- This opens a popup that guides you through the process of connecting your AWS Code Pipeline with your GitHub repository. Name your connection in the Connection name field.
- Once you’ve done that, click Connect to GitHub.
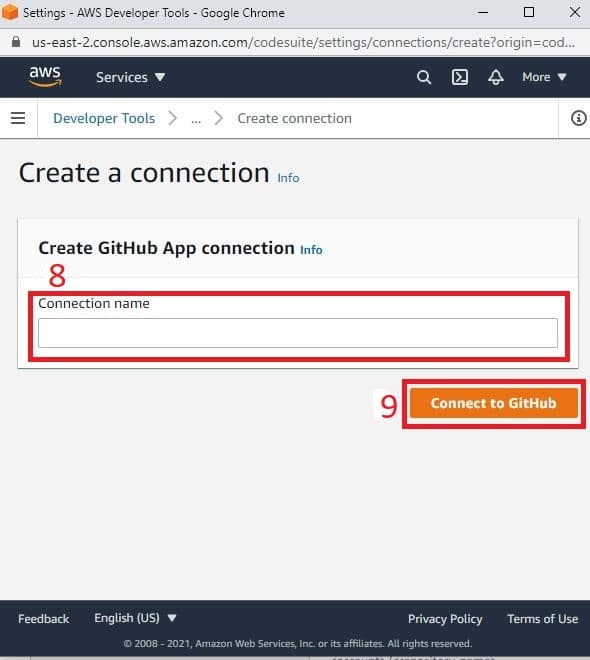
- After you’ve given your connection a name and clicked the Connect to GitHub button, the page refreshes and gives you the option to search for previous links made with GitHub or to create a new one from scratch. If this is your first time, select Install a new app.
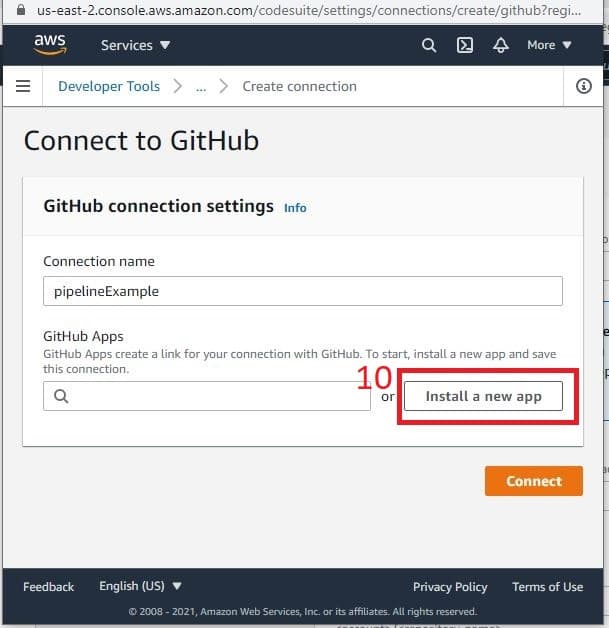
- Next, you are brought to a new page where you can choose your repositories. If you’re working on multiple projects, you can choose “Only select repositories.” In this example, I’m starting with All repositories and will fine-tune it later. Click install to continue.
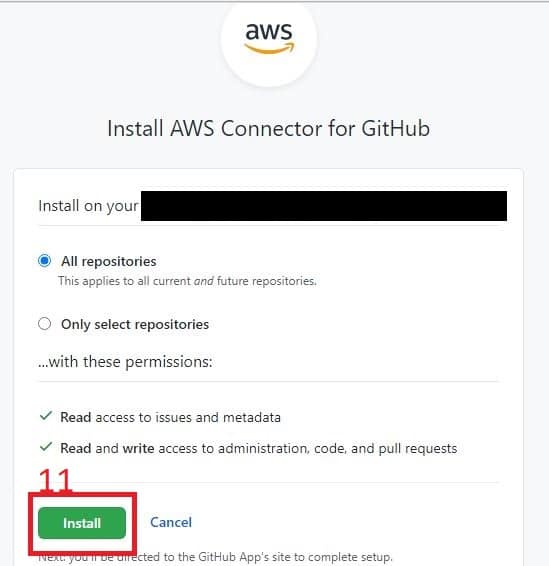
- AWS does the behind the scenes heavy lifting for you. Once it is done, your application’s ID is filled out for you. Select the Connect button.
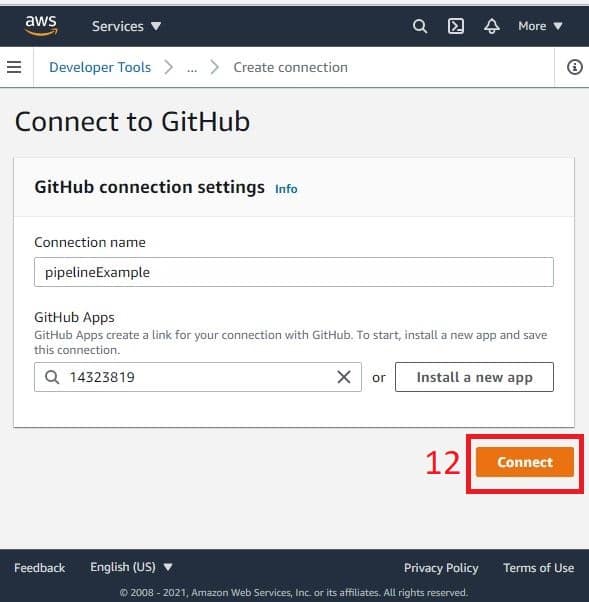
- Your popup closes, and you’ll return to your main window again. The connection field is now filled out with the connection credentials. The next step is to select the repository you want to track and the branch you want to watch.
14. Once you’ve done that, click Next.
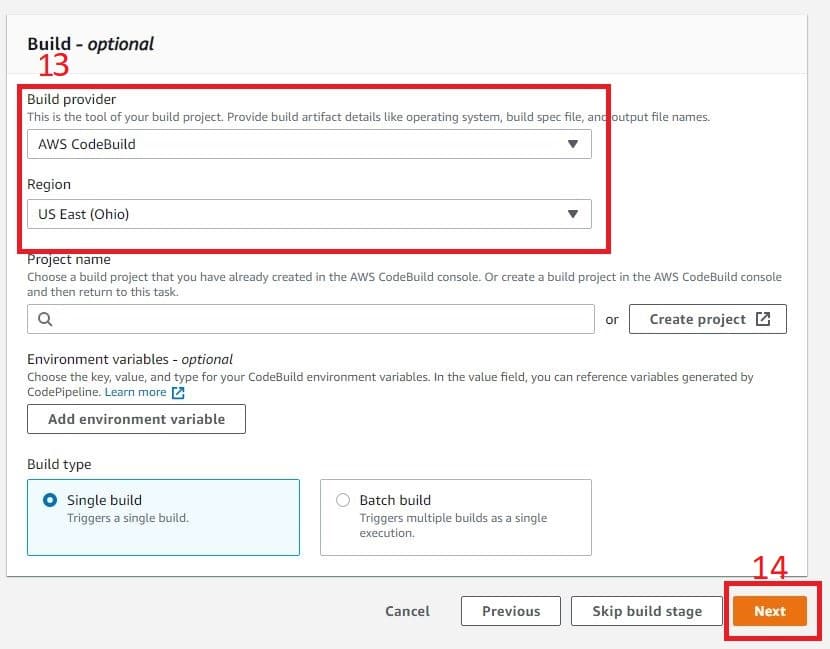
- In your code pipeline, you can also configure it to automatically build and deploy. This step is optional and can be skipped. In part, it’s because you can configure your entire pipeline with additional steps to the pipeline’s interface.
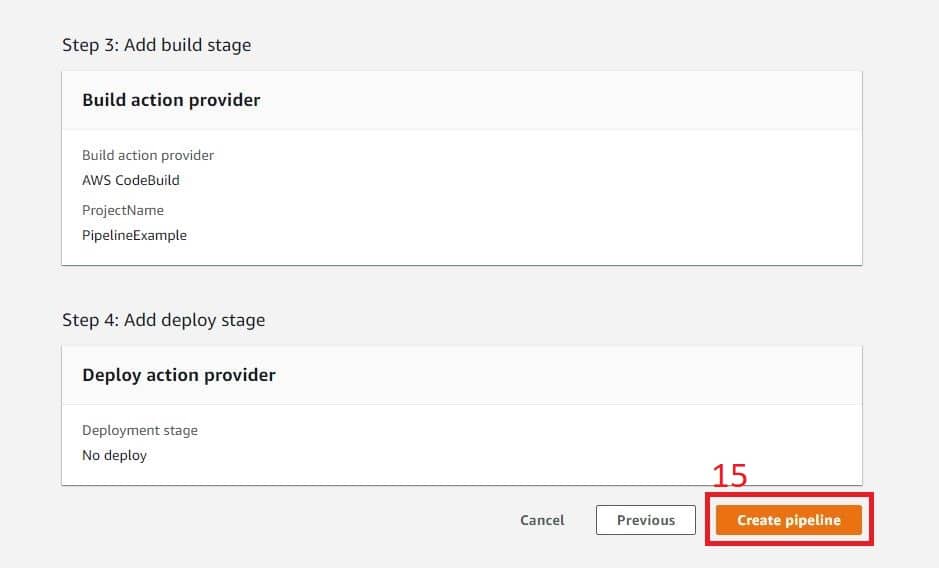
Just press Next to get your initial pipeline up and running. This takes you to the review page where you can confirm by clicking the Create Pipeline button.
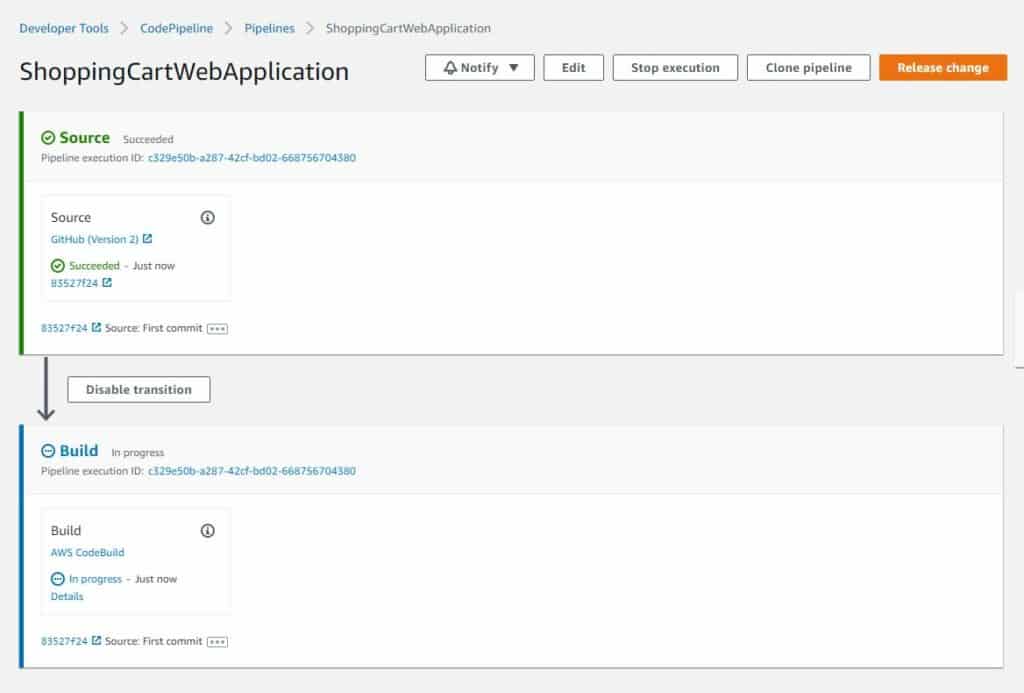
Following is an example of what a completed barebones code pipeline looks like. You can edit the pipeline with more steps to include automated testing, quality checks, and admin approval merges. If something breaks or doesn’t go as expected, the pipeline stops the process and alerts the developer about the issue.
How Code Pipelines Can Save Your Code from Falling Over
While this barebones example doesn’t look like much, it is the start of implementing a process of automated checks that ensure you are spending your time where it matters. Manual continuous delivery can take time. Cutting down on the number of steps means that any new code pushed can be automatically tested before it hits the review phases. This reduces the time needed for back and forth if something goes wrong.
The time constraints of agile software delivery mean that as developers, we’re not just performing the tasks we do faster, but also smarter through automated implementations. A code pipeline is one way to prevent long term vulnerability issues, though you should note that the security checks are only as good as your tests.
In addition to some upfront time investments in automating processes, a general security test suite is also required. These specialized tests target key vulnerabilities that an application can face such as data cleansing, memory release processes to prevent leaks, and general implementations of authentication checks.
These activities are called time investments because they cut down the repeated actions required over the duration of a project’s numerous sprints. In short, implement it once, use it indefinitely until it needs to change to accommodate the code’s growth.
We can now return to our original question: Is agile threatening code security?
The quick answer is yes – if you haven’t got the right processes and protections implemented and your developers are forced to skip a few steps due to time constraints.
The alternative answer is no – but only if repeated tasks such as testing and security-based processes are implemented before the time constraints of sprints take over a developer’s day-to-day tasks.
Code pipelines can be implemented at any time during the process as part of a sprint. The only caveat is that time must be given to developers to create and refine it.






