
All code eventually ages. At some point, you’re going to need to refactor it. Refactoring is a process of improving on code that is no longer wholly fit for purpose and has degraded due to time, changes, and general growing incompatibility with the rest of the software. While this sounds necessary, refactoring is often at the bottom of the agenda when it comes to software development.
Businesses tend to be reluctant towards the idea and resist scheduling in time for it. In part, it is because acts of refactoring are seen as going backward on something that has already been completed.
But there’s more to refactoring than just fixing old code. If all code eventually ages, how is your long term security impacted? And what exactly does refactoring do for your applications and their ability to stay relevant and resilient against new methods of breaching data security?
Nothing Is Ever Static, Including Data Security
It would be a business’ dream to never be in need of a code refactor. But this dream is only a reality if the business also doesn’t expect the external variables it serves to change. This includes user requirements, market competition, marketing initiatives, and new features. Over time, the security methods that protect your business data and software’s integrity will become obsolete as hackers and crackers break in with new techniques and exploit old vulnerabilities. Refactoring is a response to change and change is essentially inevitable.
For example, in 2012, the estimated commercial value lost to pirated software in the United States was around $9.51 billion. This was before a cloud verification model was released and software was shipped as static hard disk versions. Once the cracked code became available, the company’s ability to profit was significantly reduced and revenue was based on a user’s honesty. 20% of non compliant users using pirated software can impact a company’s profits by as much as 11%.
When Adobe moved to a cloud-based verification system in 2013, it only took one day for malicious users to crack the codes required to bypass the subscription required to use the software. However, the restructure allowed Adobe to respond and deploy fixes without having to re-release the entire software as a new version on a hard disk copy.
This not only saved the company money on remarketing the same product, but it also allowed the company to deploy better security to its current user base. When a hacker cracks a software’s security keycode, it puts other legitimate users at risk through duplications and potentially impacting their ability to use the software. There was no way to mitigate this under the old system where refactoring was not possible. However, when the option of refactoring, and therefore redeployment becomes possible, a business is able to respond faster to changes and any rising security issues it may face.
How Vulnerabilities Are Introduced — An Example
Change is often the front door entrance for a vulnerability to be introduced into an application. In a backend OOP based application, the class inheritance system is often an eventual sure-fire way to have your entire app collapse into itself. While OOP is great for small projects when the objects themselves have clear definitions and guidelines, the issue of often working with vague details can lead to improper implementations or misguided definitions.
For example, take the following hypothetical class inheritance implementation below:
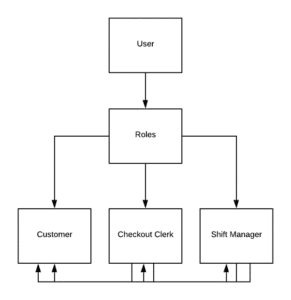
We have a User class that is a parent to a Roles class. This Roles class is further extended to three separate classes called Customer, Checkout Clerk and ShiftManager. At some point, the access permissions between Customer, CheckoutClerk, and ShiftManager become fuzzy because the latter two can also be a Customer but not the other way around, in addition to having extra perks whilst being a Customer as a CheckoutClerk and/or a ShiftManager. A CheckoutClerk can also be a ShiftManager but not every CheckoutClerk is a ShiftManager.
The code may look something like this:
While on the surface this appears simple enough, OOP duplication introduces high levels of mutability. Mutability becomes a security issue because all side effects are not accounted for, making it difficult to predict when and how a bug can occur.
Methods in the above example are duplicated with the expected same functionality, however, this is not guaranteed as the code grows over time.
A bug is an unwanted result based on a series of inputs. Bugs can lead to security vulnerabilities because it has the potential to expose private user information or execute unauthorized commands.
Refactoring is a process of rewriting or moving chunks of code into a space that allows a developer to improve and ringfence the code, isolating it or improving on the architecture.
Refactoring Is Adapting To Change
As code complexity increases through the expansion of requirements, variables, and addition of new features, refactoring becomes an adaptation tool for developers to employ. Most of the time, refactoring doesn’t just happen in isolation, but as a response to the growing need to rewrite the existing code to fit with the new trajectories and discoveries. Refactoring is also a way to deal with the accumulated mess over time. No code is perfect and the more code we have, the more our misunderstandings and miscalculated logic come to light.
How do you begin to refactor your code?
One way is to refactor by abstraction. This method is used when there is a large body of code to refactor. The goal of abstraction is to reduce duplication. While we know that duplicate code is a sign of inefficient code, it can also lead to unpatched vulnerabilities where one part of the code might be fixed, but the duplicate remains unaddressed.
In backend OOP based languages like C++ and Java, acts of abstraction are a process of implementing the pull-up/push-down methodology. The idea is simple: you pull-up your methods into a superclass to eliminate duplicate code, while push-down takes it from the superclass and moves it down into subclasses.
In the above example, moving all the methods from the subclasses up into the Users superclass will reduce any shared or duplicated methods between the children. This will allow the developer to logically contain all the various methods and apply them only as necessary. Methods that are unique to the subclasses are the ones that should remain in their current state.
In the refactored code below, the class structure is moved around with the cartCheckout() moved into the Roles class so that all the children are able to inherit it. This allows the developer to centralize the task of purchasing in one space. The relationship between CheckoutClerk and ShiftManager is established rather than just floating by itself with its own set of methods.
Here is what the refactored code can look like:
This kind of refactoring is a movement of code and doesn’t necessarily involve a physical change. However, it may be necessary to protect the application against the mess accumulated over time.
When You Don’t Need To Refactor
Sometimes, some code is just unsalvageable. Refactoring isn’t required if you’re building a completely new application from start to finish. In this case, starting from scratch would be more efficient and robust for your architectural integrity.
Refactoring is also a process of weighing up the time/cost factor against writing completely new code. Bridge patterns are often used to create connections between old and new code. This often offers a better solution for your software and its long term security as it mitigates unsolvable issues caused by the previous implementations.
For example, you might have a third-party payment system implemented. However, your backend triggers a successful payment status before the status is received, resulting in false positives in the event of a declined card transaction. This can result in lost revenue over time. You know where the trigger is and its refactoring involves a process of moving the trigger code after the payment status is properly confirmed. This refactor fixes the bug and improves the overall security of your application by preventing purposeful triggering of card declines to gain access to the checkout product.
In contrast, if the trigger is unlocatable and the connection flow process cannot be established because the code contains too much legacy, this would be a case of a complete rewrite rather than an actual refactor.
Final Thoughts
Nothing remains static for long when it comes to software development. Things change and as a result, the code also changes. When the codebase grows, so will your vulnerabilities through various bugs and loopholes that can be exploited by malicious users.
While there is the usual set of server-side and general security breaches like cross-site scripting and cookie hijacking, a major vulnerability in any application is when a bug is discovered and exploited. Refactoring can reduce this potential by creating better architecture, reduce repetition, increase cohesiveness, establish class relationships, and how methods are consumed.






